Häufigkeitsverteilung von diskreten Daten
Gegeben sei ein Zufallsexperiment mit einer diskreten Zufallsvariablen , welche die möglichen Werte besitzt. Konkret, wir würfeln einmal einen fairen Würfel und setzen ="beobachtete Zahl", so dass die möglichen Werte sind. Das Experiment werde Mal durchgeführt, was zum folgenden Datensatz führen könnte:
Die Häufigkeitsverteilung des Datensatzes ist eine Tabelle, die aufzeigt, wie oft jeder mögliche Wert von auftritt
Beachte, dass wir die Zählungen in der Regel als relative Häufigkeiten oder Prozentsätze der Gesamtzahl der Datenpunkte im Satz ausdrücken. Wir können auch ein Diagramm der Häufigkeitstabelle (unter Verwendung der relativen Häufigkeiten) erstellen, das sogenannte Balkendiagramm. Die möglichen Werte im Datensatz werden entlang der -Achse und die relativen Häufigkeiten entlang der -Achse angegeben:
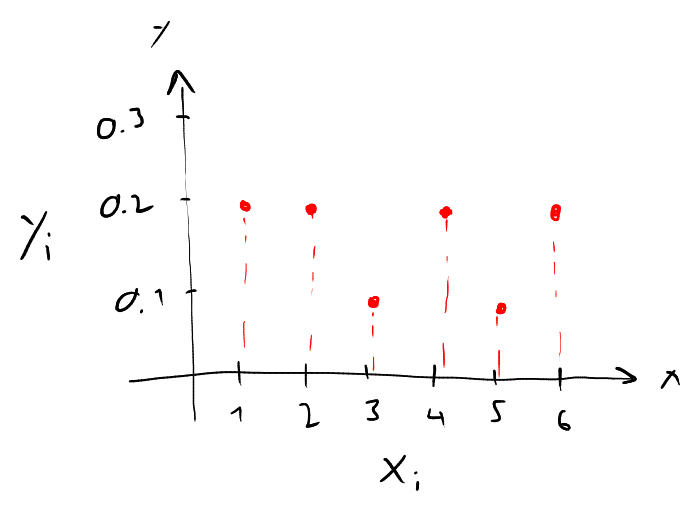
Beachte, dass wir das Balkendiagramm hier nicht mit Balken sondern mit Punkten zeichnen. Beides ist üblich. Wir brauchen hier Punkte, um Balkendiagramme klar von Histogrammen zu unterscheiden (siehe nächstes Kapitel), die immer mit Balken gezeichnet werden. Der wesentliche Unterschied: Beim Balkendiagramm hat die Balkenbreite keine Bedeutung, beim Histogramm schon.
Wie sieht das Balkendiagramm aus, wenn wir die Anzahl der Datenpunkte erhöhen, sagen wir ? Mit anderen Worten, was passiert, wenn wir das Experiment mal wiederholen? Nun, per Definition der Wahrscheinlichkeit wird die relative Häufigkeit die Wahrscheinlichkeit für die Beobachtung einer (oder ) annähern, also haben wir dann
Für sind die Balkenhöhen also gerade die Wahrscheinlichkeitsfunktion der Zufallsvariablen .
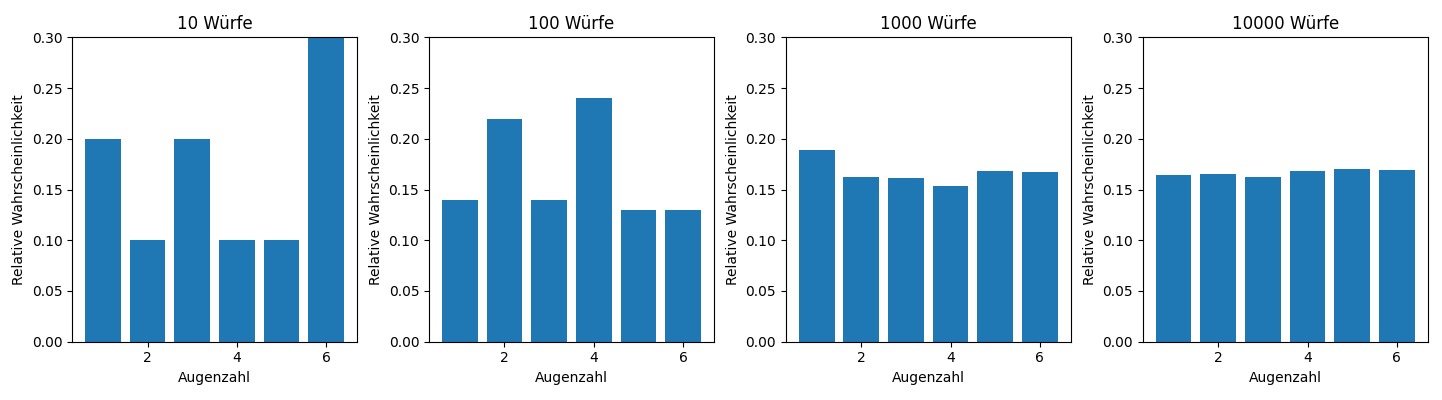
Fassen wir zusammen:
Gegeben sei eine diskrete Zufallsvariable , der durch ein -mal wiederholtes Zufallsexperiment erzeugt wird, und eine diskrete Zufallsvariable mit den möglichen Werten . Der Datensatz könnte also wie folgt aussehen:
Seien die relativen Häufigkeiten der Werte im Datensatz. Die Wahrscheinlichkeitsfunktion von ist definiert als
Dann approximieren die relativen Häufigkeiten der Datenpunkte im Datensatz (die Balkenhöhen im Balkendiagramm) die Wahrscheinlichkeitsfunktion von :
Je grösser der Datensatz (d.h. ), desto besser ist diese Approximation.
Eine Münze mit wird -mal geworfen. Es sei ="Anzahl Kopf". Der Versuch wird mal durchgeführt. Bestimme die ungefähre Häufigkeitsverteilung von dem erhaltenen Datensatz, und skizziere das Balkendiagramm.
Solution
Dies ist eine Binomialverteilung, wobei und die Erfolgswahrscheinlichkeit ist . Wir haben also
Führen wir das Experiment Mal durch, so nimmt zufällig die Werte ,,,, und an. Die wird in dieser Experimente angenommen (relative Häufigkeit , absoluten Anzahl ist also ), die wird in der Fälle angenommen (relative Häufigkeit 0.422, absolute Anzahl ), und so weiter. Wir haben also die folgende Häufigkeitstabelle:
Dies sind nur ungefähre Werte, da die Wahrscheinlichkeiten nur dann die Prozente angeben, falls die Anzahl Experiment extrem hoch ist, also viel höher als .
