Häufigkeitsverteilung von kontinuierlichen Daten
Wenn die Zufallsvariable kontinuierlich ist (daher Werte in einem Intervall produziert), und wir mal das Experiment wiederholen, bekommen wir einen kontinuierlichen Datensatz mit Datenpunkten. Der grosse Unterschied zum diskreten Datensatz ist der, dass wenn wir keine Häufigkeitstabelle aufstellen können, die alle möglichen Werte von auflistet (das haben wir im diskreten Fall getan mit dem Balkendiagramm). Ein anderes Problem ist, dass ein Datenpunkt im Datensatz kaum mehr als einmal vorkommen wird!
Es lohnt sich, diesen letzten Punkt zu verdeutlichen, und die Konsequenzen zu diskutieren. Wir machen das mit Hilfe eines kontinuierlichen Datensatzes, der sich aus der Messung des Gewichts von M&Ms (in g) ergibt:
Wir stellen uns die Produktion der M&Ms als einen Zufallsprozess vor, der von der Maschine verursacht wird. Jedes M&M sieht ein bisschen anders aus, wiegt ein bisschen anders, und so weiter, aufgrund kleiner Unvollkommenheiten der Maschine und des Produktionsprozesses. Wir haben also das Zufallsexperiment "produziere ein M&M", und wir verwenden die kontinuierliche Zufallsvariable ="Gewicht des M&M", wobei die möglichen Werte (Gewichte) im Intervall liegen. Wir wiederholen das Experiment Mal, um könnten zum Beispiel den folgenden Datensatz erhalten:
Ein M&M im Datensatz hat das Gewicht . Es ist gut einzusehen, dass es höchst unwahrscheinlich ist, dass ein zweites M&M mit dem exakt gleichen Gewicht im Datensatz enthalten ist. Die Maschine müsste nochmals ein M&M mit genau diesem Gewicht produzieren, was sehr unwahrscheinlich ist). Das Bestimmen der relativen Häufigkeit aller M&M's mit genauen Gewicht wird also nichts dazu beitragen, Erkenntnisse über die Gewichtsverteilung des Datensatzes zu gewinnen. Bei einem grossen Datensatz ( gross) ist die relative Häufigkeit, den Punkt zu beobachten, im wesentlichen (), und für einen unendlich grossen Datensatz () ist somit
Das obige Beispiel demonstriert zweierlei für eine kontinuierliche Zufallsvariable :
-
für alle
-
bedeutet nicht, dass der Wert nie beobachtet werden kann. Das Gwicht im obigen Beispiel kam ja im Datensatz vor. Es bedeutet aber, dass eine beobachtete Grösse nie mehr als einmal vorkommen kann (mit an Sicherheit grenzender Wahrscheinlichkeit). Der Grund dafür ist, etwas salop formuliert, dass es unendlich viele mögliche Werte zwischen und gibt (überabzählbar viele). Selbst bei unendlich vielen Wiederholungen des Experiments werden wir daher jeden spezifischen Wert von höchstens einmal beobachten.
Zum Vergleich: Bei einer diskreten Zufallsvariable (z.B. Würfelwurf mit ="gewürfelte Zahl") gibt es nur endlich viele mögliche Werte von . Wiederholt man das Experiment oft genug, wird jeder mögliche Wert mehrfach vorkommen, und .
Da im kontinuierlichen Fall es wenig Sinn macht, nach der Häufigkeit (oder Wahrscheinlichkeit) eines einzelen Punktes zu Fragen, machen wir das nächst Beste. Wir bestimmen, wie viele M&M's in einem kleinen Intervall Intervall liegen, z.B. von , von , von , und so weiter. Diese kleinen Intervalle werden Klassen (englisch bins) genannt. Die Breite des Intervalls wird als Klassenbreite (englisch bin-size) bezeichnet, und wird mit (also ) bezeichnet.
Wenn wir also zählen, wie viele M&Ms in jede Klasse fallen, erhalten wir zum Beispiel die folgende Häufigkeitsverteilung der Daten:
Bei kontinuierlichen Daten sind wir in der Regel an der Dichte interessiert. Dies ist die die relative Häufigkeit geteilt durch die Klassenbreite (4. Spalte in der Tabelle oben):
Die grafische Darstellung der Dichten wird Histogramm genannt. In einem Histogramm werden die Klassen auf der vertikalen Achse aufgezeichnet, und über jeder Klasse wird ein Balken (mit gleicher Breite wie die Klasse, ) gezeichnet, dessen Höhe gerade der Dichte entspricht. Es gilt somit:
Die Fläche des Balkens, , ist die relative Häufigkeit der Datenpunkte in der Klasse .
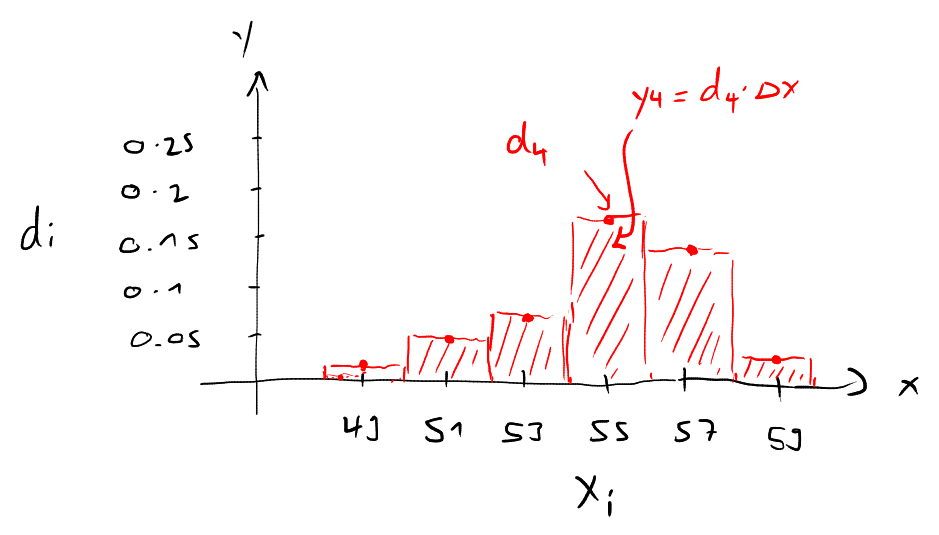
Die Fläche des Balkens approximiert also die Wahrscheinlichkeit, dass der beobachtete Wert in der Klasse liegt:
Je mehr Datenpunkte im Datensatz sind, desto besser ist diese Approximation.
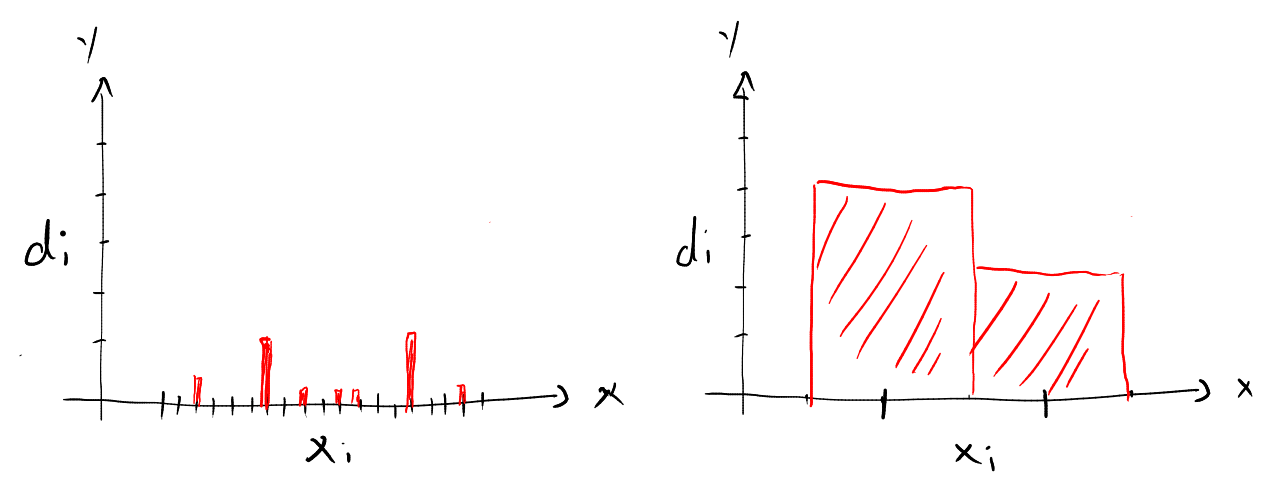
Die Wahl der Klassengrösse ist sehr wichtig. Wenn sie zu klein gewählt wird, gibt es viele Klassen, die keine Daten enthalten, und ein paar wenige, die vielleicht einen oder zwei Datenpunkte enthalten (siehe unten, links). Wird die Klassengrösse zu gross gewählt, gehen Details über die Verteilung der Datenpunkte verloren (siehe unten, rechts). Woher wissen wir also, welche Klassengrösse wir verwenden sollen? Es gibt Methoded, die ideal Klassengrösse zu bestimmen, wir gehen aber nicht darauf ein. Wir begnügen uns damit, die Klassengrösse durch Ausprobieren zu bestimmen, daher wir probieren verschiedene Klassengrössen aus, bis das resultierende Histogramm "irgendwo" zwischen diesen beiden Extremen liegt (siehe Histogramm oben).
Warum wollen wir, dass die Fläche des Balkens die relative Häufigkeit oder Wahrscheinlichkeit repräsentiert? Dies scheint etwas willkürlich zu sein. Wir erinnern uns aber daran, dass Balkenflächen mit dem Integral zu tun haben, und genau das wird hier bezweckt. Wir können nun die Berechnung von Wahrscheinlichkeiten einer kontinuierlichen Zufallsvariable mit Integralrechnung verbinden. Dies wird im nächsten Kapitel diskutiert.
Betrachte den folgenden kontinuierlichen Datensatz (Körpergrösse der Schüler in ):
Zeichne drei Histogramme mit den unten angegeben Klassengrössen. Beginne bei und ende bei .
Solution
:
:
:
