Normalverteilte Daten
Gegeben seien kontinuierliche Datenpunkte:
Zum Beispiel, das Gewicht von M&Ms:
Die Datenpunkte sind normalverteilt, falls bei genügend vielen Datenpunkten und genügend kleiner Klassenbreite das Histogramm durch eine Normalverteilung approximiert werden kann, wobei der Parameter gerade der Mittelwert der Daten ist, und der Parameter die Standardabweichung, daher:
Beachte, dass wir nun bei der Standardabweichung durch teilen, und nicht mehr durch . Falls gross ist, ist der Unterschied des Resultats aber vernachlässigbar klein. Zum Beispiel, teile ich durch oder durch , die Zahl, die ich erhalte, ist fast gleich gross ( versus ).
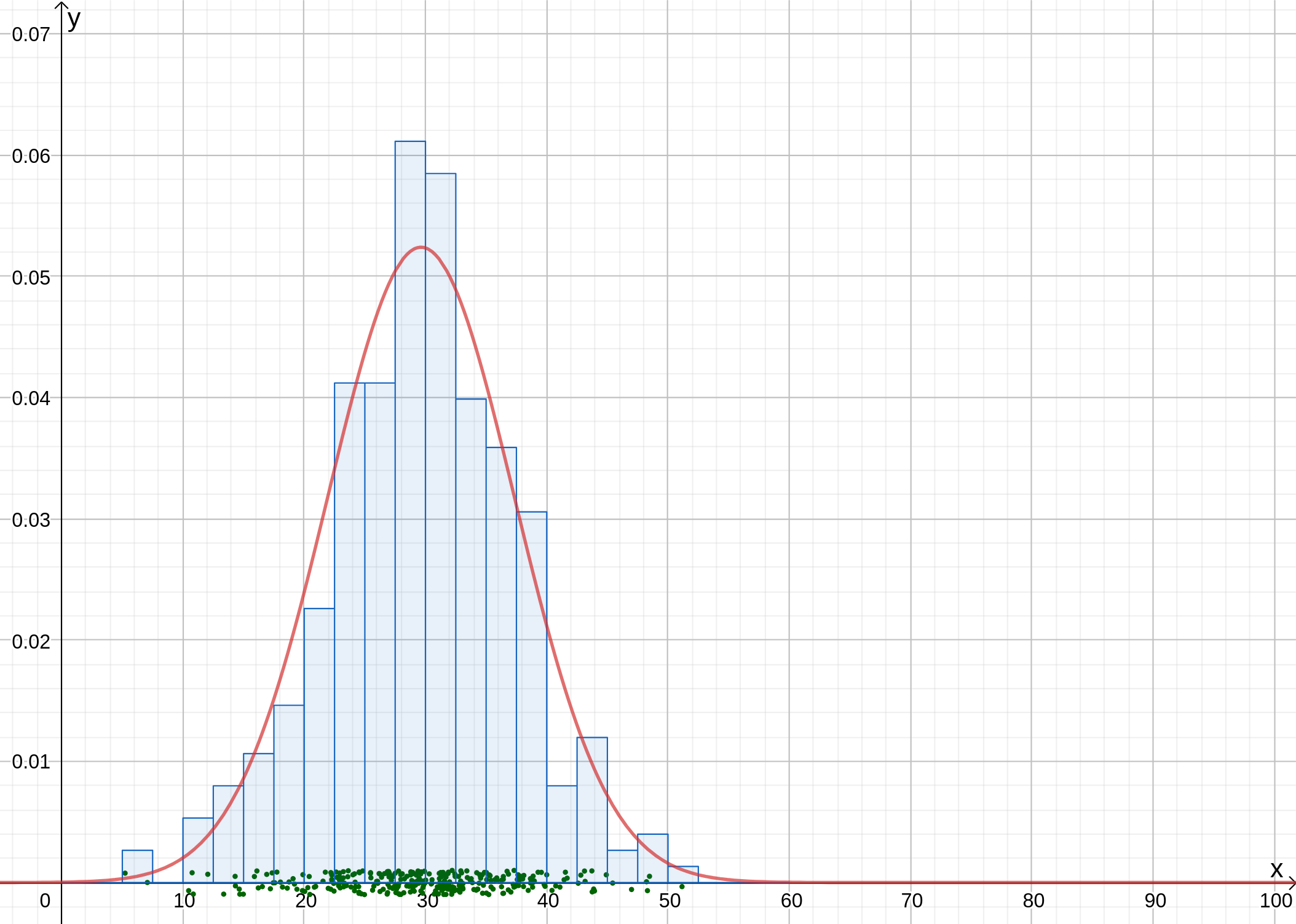
Unten ist die Häufigkeitstabelle eines normalverteilten Datensatzes gegeben. Der Mittelwert der Daten ist , die Standardabweichung . Ebenfalls gezeigt ist das Histogramm und die Normalverteilung .
-
Kontrolliere ob die Häufigkeitstabelle und das Histogramm übereinstimmen (vergleiche die Dichten).
-
Bestimme die Parameter und der Normalverteilung.
-
Basierend auf der Normalverteilung, bestimme die (ungefähre) Wahrscheinlichkeit, dass ein zufällig gewählter Datenpunkt zwischen und liegt.
-
Basierend auf der Normalverteilung, bestimme ein (ungefähres) Intervall so, dass ein zufällig gewählter Datenpunkt mit Wahrscheinlichkeit in diesem Intervall liegt.
Show
Lösung
-
Um die Dichte zu bekommen, müssen wir die Häufigkeiten durch teilen (relative Häufigkeit), und dann auch noch durch die Klassenbreite . Zählen wir die Häufigkeiten zusammen, so bekommen wir , und die Klassenbreite ist . Wir bekommen also die Dichten
Ein Vergleich mit dem Histogramm zeigt, dass die Dichten übereinstimmen.
-
Die Parameter der Normalverteilung sind (der Mittelwert der Daten) und (die Standardabweichung der Daten).
-
Es ist und . Die Wahrscheinlichkeit, dass ein Datenpunkt in diesem Intervall liegt ist die Fläche unter der Kurve von und, und das ist (siehe vorhergehendes Kapitel). Dies ist nur ein ungefährer Wert, da die Normalverteilung das Histogramm nur approximiert.
-
Siehe vorhergehendes Kapitel: es ist und
Aufgabe 2
Messungen desGewichts von Melonen ergeben einen Mittelwert von und eine Standardabweichung von . Das Histogramm der Gewichte zeigt, dass die Gewichte ungefähr normalverteilt sind.
- Finde die Parameter der Normalverteilung .
- wie viele Melonen, ungefähr, haben ein Gewicht grösser als ?
- Zwischen welchen Gewichten and liegen etwa der Melonen?
Show
Lösung 2
- hat die Parameter
- Die Wahrscheinlichkeit, dass eine Melone grösser ist also ist die Fläche unter der Kurve von nach . Wegen , ist diese Fläche gerade . Da es Melonen hat, sind also ungefähr Melonen schwerer als .