Mean and standard deviation of data
Consider a list of data, such as the grades of a student:
The average or mean value of the grades is obtained by forming the sum of the grades, and dividing by the number of grades:
The average value indicates what the typical value is, or the value that "lies somewhere in the middle". The mean value thus calculates a "place" or "position" on the number line, and is therefore also called measure of position. There are several other such measures, e.g. the median, or the quantiles. However, we will not discuss them here.
Another interesting measure expresses how much the data vary. Another student with the same average score of but with a much smaller variance (e.g. five times ) clearly shows a different performance. To qualify such variations in the data, we use the standard deviation. Since the standard deviation measures dispersion, it is also called a measure of dispersion. Again, there are several other measures of dispersion.
The formula for calculation the standard deviation is shown below:
This formula looks complicated, but its meaning is simple enough to understand: it is the average deviation of the data points from the mean (see figure below).
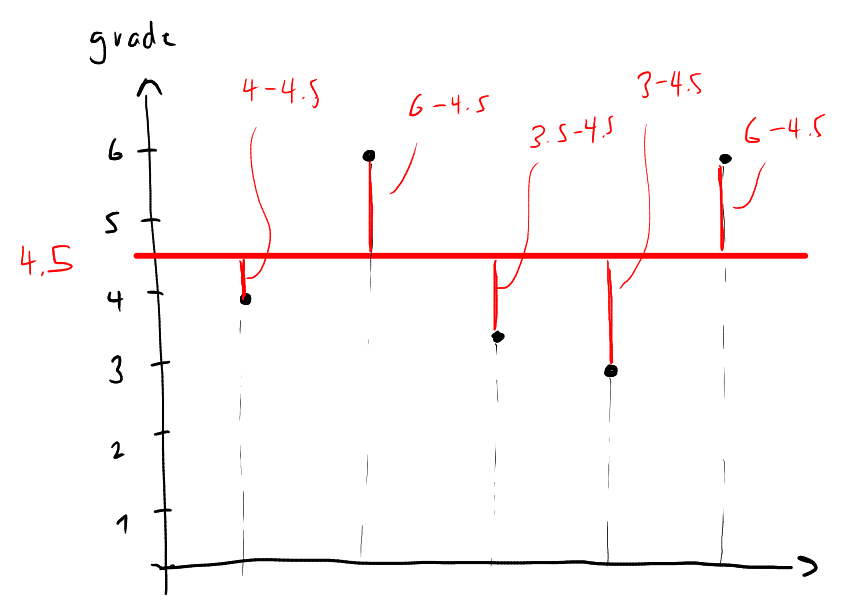
The squared term is the difference between the mean and the data point , squared. We square it, so that the difference is always positive. So the formula calculates the average of the squared differences between the mean and the data points, and takes the root of this average.
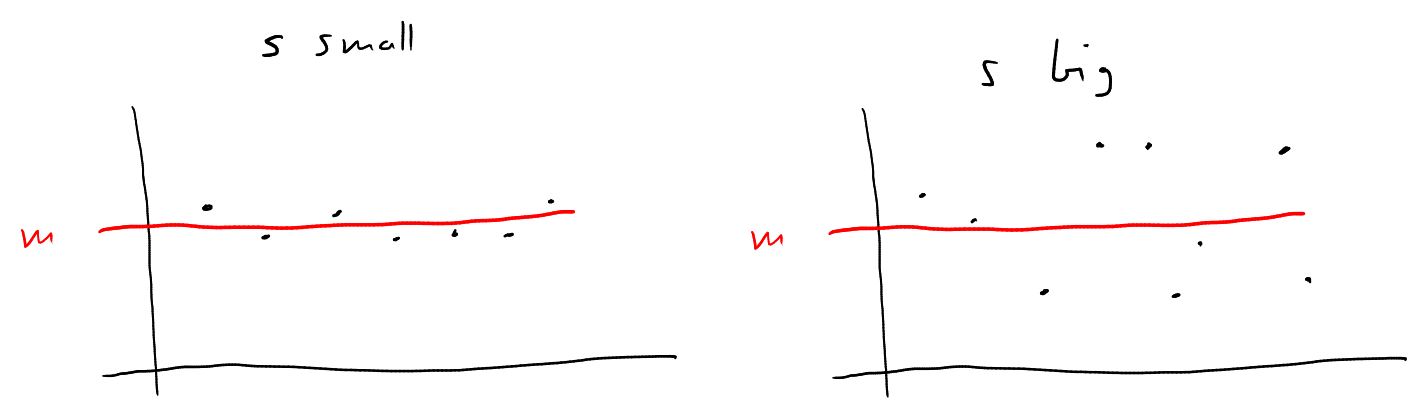
Clearly, a standard deviation means that there is no variation at all, and all data points equal exactly . The bigger is, the more will the data points deviate from the mean (see figure below).
Some clarifications:
-
Why do we want to use positive differences only? Because if we simply take the difference, the average of these differences will always be , although the data points vary wildly about the average (Can you explain why this is true in general?). For example, look at these data points:
The mean is
Clearly there is some variation, and indeed the standard deviation is far from zero with
However, the average of the difference is zero because some of the differences are positive, others are negative:
-
Why the root? Often data points have units, for example metres. The average is also in metres, and we want the standard deviation also to be in metres. Without taking the root, however, the standard deviation is in square metres, because we square the differences, which are also in metres.
Here is a general definition of the average and the standard deviation:
Consider data points . The average or mean value of the data points is
The standard deviation of the data points (from the mean) is
The variance of the data points is the squared standard deviation:
-
Determine the mean, standard deviation and variance of the data points
-
Consider melons, of which have weight , have weight , and the remaining have weight . Determine the mean weight and the standard deviation.
Solution
-
-
melons have weight , melons have weight , and melons have weight . So we have
The solution of the second exercise 1.2 highlights an interesting insight, which will be important in the next chapter: If many of the data points are equal, we can use the percentages of equal data points to calculate and very easily. In fact, we do not even have to know the total number of data points. Here is an example.
Assume that of the data points have the value , and the remaining of the data points have the value . The mean and the standard deviation of the data points are:
Do you understand why? Uncollapse to see the explanation.
Solution
Let as assume that there are data points (e.g. ). There are data points with value and data points with value . There are also squared differences and squared differences . Thus