Monoalphabetische Verfahren
Die klassischen Verfahren haben den Nachteil, dass sich Sender und Empfänger über den Schlüssel verständigen müssen. Dies entfällt bei den Public-Key-Systemen, die seit 1976 entwickelt werden. Das bekannteste unter ihnen - das RSA-Verfahren - verwendet die Primfaktorzerlegung natürlicher Zahlen. Es ist nur so lange sicher, wie es keine wesentlich schnelleren Algorithmen zur Primfaktorzerlegung als die heute bekannten gibt.
Eine sehr einfache Verschlüsselung erhalten wir, indem wir jedem Buchstaben ein festes Symbol zuordnen - diese Verfahren heissen monoalphabetisch.

Bei der monoalphabetischen Chiffrierung wird das Klartextalphabet permutiert - die Buchstabenanordnung wird vertauscht. Unter der Annahme, dass das verwendete Alphabet 26 Buchstaben besitzt, erhalten wir also
Möglichkeiten der Anordnung der Buchstaben.
Die CAESAR-Cipher
Zu den einfachsten Chiffren gehört die Verschiebechiffre, die schon von Caesar verwendet wurde. Hierbei werden nur die Buchstaben in ihrer Reihenfolge verschoben. Einen solchen Geheimtext können wir einfach brechen, da für ein beliebiges Wort nur alle möglichen 26 Verschiebungen betrachtet werden müssen, um es zu entschlüsseln. Betrachten wir zum Beispiel RBC, so ergibt das Wort ist einen Sinn.
Verschlüssle
veni vidi vici
mit Caesar.
Solution
YHQL YLGL YLFL
Schreibe Code, der eine Message mit einem beliebigen, festgelegtem Shift verschlüsselt.
Solution
Ein Beispiel ist:
cipher = ""
message = "Testmessage aBYz"
shift = 1
for k in range(len(message)):
if message[k].islower():
cipher = cipher + chr((ord(message[k]) - 97
+ shift) % 26 + 97)
elif message[k] == " ":
cipher += " "
else:
cipher += chr((ord(message[k]) - 65 + shift)
% 26 +65)
print(cipher)
Entschlüssle den mit Caesar verschlüsselten Text JDLXV MXOLXV FDHVDU.
Solution
Mit obigem Programm probiert man verschiedene Shifts durch. So lange, bis der Text sinnvoll scheint. Vielleicht startet man mit der Vermutung, dass vermutlich Shift verwendet werden muss. Dies ergibt dann gaius julius caesar.
Versuche nun den folgenden berühmten Satz zu dechiffrieren:
LFK NDP VDK XQG VLH JWH
Solution
Werden (kommentiert) in Mathematica oder Python erledigt.
Zu monoalphabetischen Verschlüsselungsverfahren:
a) Wie viele verschiedene Transpositionscipher gibt es?
b) Wie viele Substitutionscipher gibt es?
c) Wieso ist es, trotz der vielen Möglichkeiten, im Allgemeinen leicht, eine Substitutionscipher zu knacken?
d) Wie könnte man die Schwachstelle einer monoalphabetischen Cipher cachieren?
Solution
a) Falls man die Identität inkludiert, so hat man mögliche Shifts des Alphabets.
b) Beginnend mit A hat man mögliche Kandidaten als Substitution. Für den nächsten Buchstaben "B" sind es dann noch , weil einer an A vergeben wurde. So fährt man sinngemäss fort und erhält Möglichkeiten. Das sind sehr sehr viele.
c) Weil, angenommen dass die Verfassersprache bekannt ist, die für die Sprache charakteristischen Buchstabenhäufigkeiten erhalten bleiben. Sie werden bloss durch andere "Zeichen" repräsentiert. Beispielsweise ist im Deutschen das E mit einer Häufigkeit von gut dominant. Kennt man das E, so lassen sich häufige Konstellationen (EI, DIE, etc.) erschliessen und anschliessend zusammen mit weiteren, häufigen Buchstaben (z.B. T, S, N, \dots) lässt sich der Text schliesslich knacken.
d) Man versucht die Buchstabenhäufigkeiten zu verschleiern, indem beispielsweise mit wechselnden Shifts gearbeitet wird oder für häufig auftretende Buchstaben entsprechend mehrere Cipher-Zeichen eingesetzt werden.
Tauschchiffre
Eine weitere Möglichkeit zur Verschlüsselung bietet die Substitutioncipher. Hierbei wird nicht einfach das gesamte Alphabet verschoben, sondern die Buchstaben untereinander vertauscht. Mathematisch ausgedrückt heisst das: jedem Buchstabe des Klartextalphabetes wird gemäss der Reihenfolge die entsprechende natürliche Zahl zugeordnet. Multiplizieren wir den Wert eines jeden Klartextbuchstaben mit einer frei wählbaren Zahl, erhalten wir ein neues (im Allgemeinen nicht eindeutiges) Geheimtextalphabet. Soll diese Abbildung eindeutig sein, müssen wir beachten, dass die Geheimzahl und die Anzahl der Klartextbuchstaben zueinander teilerfremd sind. Für ein Alphabet mit Buchstaben sind also "nur" die Faktoren , , , , , , , , , , und möglich. Wählen wir zum Beispiel als Faktor, so entsteht das Alphabet in untenstehender Tabelle (Substitution kommentiert).
| a | b | c | d | e | f | g | h | i | j | k | l | m |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | F | I | L | O | R | U | X | A | D | G | J | M |
| n | o | p | q | r | s | t | u | v | w | x | y | z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | S | V | Y | B | E | H | K | N | Q | T | W | Z |
Häufig wird die Methode des Schlüsselwortes verwendet, d.h. Sender und Empfänger vereinbaren ein Schlüsselwort und einen Schlüsselbuchstaben - dies kann z.B. das fünfte Wort in der Bibel und der zweite Buchstabe des dritten Wortes sein. Somit kann die Chiffrierung jeden Tag mit anderen Voraussetzungen begonnen werden. Zur Vereinfachung wird folgendes angenommen:
Schlüsselwort:
GEHEIMSCHRIFTSchlüsselbuchstabe:e
Zur Chiffrierung werden nun die im Schlüsselwort mehrfach auftretenden Buchstaben bei Wiederholung gestrichen, wir erhalten also
GEHIMSCRFT
Dann wird der Rest des Schlüsselwortes unter das Klartextalphabet geschrieben, beginnend beim Schlüsselbuchstaben. Es folgt das Auffüllen der restlichen Alphabetbuchstaben.
| a | b | c | d | e | f | g | h | i | j | k | l | m |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| W | X | Y | Z | G | E | H | I | M | S | C | R | F |
| n | o | p | q | r | s | t | u | v | w | x | y | z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | A | B | D | J | K | L | N | O | P | Q | U | V |
Ein praktisches Beispiel
Wir wollen unserem Verleger die aktuelle Version des neuen Romans schicken. Da der benutzte Weg sehr unsicher ist, soll das Stück verschlüsselt werden. Als Schlüsselwort wurde JAMES BOND vereinbart, der Schlüsselbuchstabe soll das q sein. Wir entfernen zunächst das Leerzeichen aus dem Schlüsselwort und schreiben das Schlüsselwort beginnend beim Buchstaben q auf. Anschliessend ergänzen wir die fehlenden Geheimtextbuchstaben, so dass keiner doppelt vorkommt:
| a | b | c | d | e | f | g | h | i | j | k | l | m |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F | G | H | I | K | L | P | Q | R | T | U | V | W |
| n | o | p | q | r | s | t | u | v | w | x | y | z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X | Y | Z | J | A | M | E | S | B | O | N | D | C |
Nun wandeln wir schrittweise den Klartext in den Geheimtext um, indem wir für den jeweiligen Klartextbuchstaben den darunter stehenden Geheimtextbuchstaben verwenden.
Der abgeschlossene Roman
IKA FGPKMHQVYMMKXK AYWFX
"Los, hierher ihr beiden!! Wollt ihr wohl hoeren?"
VYM, QRKAQKA RQA GKRIKX!! OYVVE RQA OYQV QYKAKX?
"Hierher sag' ich! Ja, so ist es brav"
QRKAQKA MFP' RHQ! TF, MY RME KM GAFB
"So - und jetzt macht ihr schoen Platz"
MY - SXI TKECE WFHQE RQA MHQYKX ZVFEC
"Na bitte! Und jetzt bei Fuss! Na los"
XF GREEK! SXI TKECE GKR LSMM! XF VYM
"Bei Fuss hab' ich gesagt"
GKR LSMM QFG' RHQ PKMFPT
"Fuu... Mein Gott, Riebesehl" , stoehnt Gatti
"LSS... WKRX PYTT, ARKGKMKQV" , MEYKQXR PFEER
"kannst du nicht einmal deine Socken anziehen
"UFXXME IS XRHQE KRXWFV IKRXK MYHUKX FXCRKQKX
wie jeder andere auch?"
ORK TKIKA FXIKAK FSHJ?
(aus STERN Hamburg; Heft 29/94 S. 74)
Das Entschlüsseln monoalphabetischer Texte
Um einen solchen Geheimtext zu knacken, müssen zwei Bedingungen erfüllt sein. Zum einen muss der Klartext in einer natürlichen Sprache verfasst worden sein, und zum zweiten ein längeres Stück des Geheimtextes vorliegen. Die Analyse des Textes beruht auf der Häufigkeitsverteilung von Buchstaben und Bigrammen in der Verfassersprache. Für Deutsch sieht die Verteilung wie in unten stehender Tabelle aus.
| Buchstabe | Häufigkeit | Buchstabe | Häufigkeit | Bigramm | Häufigkeit |
|---|---|---|---|---|---|
| a | 6.47 % | n | 9.84 % | en | 3.88 % |
| b | 1.93 % | o | 2.98 % | er | 3.75 % |
| c | 2.68 % | p | 0.96 % | ch | 2.75 % |
| d | 4.83 % | q | 0.02 % | te | 2.26 % |
| e | 17.48 % | r | 7.54 % | de | 2.00 % |
| f | 1.65 % | s | 6.83 % | nd | 1.99 % |
| g | 3.06 % | t | 6.13 % | ei | 1.88 % |
| h | 4.23 % | u | 4.17 % | ie | 1.79 % |
| i | 7.73 % | v | 0.94 % | in | 1.67 % |
| j | 0.27 % | w | 1.48 % | es | 1.52 % |
| k | 1.46 % | x | 0.04 % | ||
| l | 3.49 % | y | 0.08 % | ||
| m | 2.58 % | z | 1.14 % |
Vorgehensweise beim Entschlüsseln ist hier kommentiert.
Man zählt die Häufigkeiten der Buchstaben im Geheimtext und findet so e und n und die Menge . Durch Auszählen der Bigramme kann man dann r,i,t,s,a isolieren und schliesslich über ch noch c und h bestimmen, da das Bigramm hc fast nie vorkommt. Die Buchstaben e,n,i,s,r,a,t,c und h machen bereits rund 65% des Textes aus. Der Rest ergibt sich durch Probieren.
Ein weiteres Beispiel
Gegeben ist folgender monoalphabetisch verfasster Geheimtext:
FWJNKYICW CAFFL NGXJMHGTK IWLLG FGMTG KYIPMGHGJFNLLGJ PMGZGJ FWR FMHJWGTG FGMTG CWLVGT IWXG MYI HGHGT VRALU GMTHGLWNKYIL ZGTGT HMTH GK KAPMGKA TMYIL XGKATZGJK PWK FWYIL ZGMT INTZ JWNYIL GJ MFFGJ TAYI KA OMGR
- Zählen der einzelnen Buchstaben.
| Buchstabe | Wert | Buchstabe | Wert |
|---|---|---|---|
| A | 7 | N | 6 |
| B | 0 | O | 1 |
| C | 3 | P | 4 |
| D | 0 | Q | 0 |
| E | 0 | R | 3 |
| F | 11 | S | 0 |
| G | 30 | T | 15 |
| H | 8 | U | 1 |
| I | 11 | V | 2 |
| J | 10 | W | 11 |
| K | 11 | X | 3 |
| L | 12 | Y | 8 |
| M | 14 | Z | 5 |
Der Buchstabe G tritt am häufigsten auf, deshalb vermuteten wir: G=e. Da n der zweithäufigste Buchstabe ist, sehen wir, das n entweder T oder M sein muss. Aus der Gleichverteilung der Buchstaben s,i,r,a,n,t folgt, dass sie T,M,L,F,I,K,J oder W sind.
und
- Zählen der Bigramme, die mit
ebeginnen, alsoe?=G?.
| GX | GT | GM | GH | GJ | GZ | GL | GK |
|---|---|---|---|---|---|---|---|
| 1 | 6 | 4 | 1 | 6 | 1 | 1 | 3 |
Aus der Häufigkeitsverteilung der Bigramme folgt
und damit n = T und r = J oder umgekehrt.
Wir suchen nun nach ei und ie, da diese mit gleicher Häufigkeit vorkommen. So finden wir i = M; damit muss aber s = K sein.
- Zählen der Bigramme, die mit
eenden, also?e=?G.
| NG | HG | LG | FG | TG | MG | ZG | WG | VG | XG |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 2 | 3 | 4 | 4 | 4 | 1 | 1 | 2 |
Da ie = MG und ne = TG bereits feststehen, gilt
Durch Vergleich mit obigen Mengen erhalten wir: , , .
- Zählen der am häufigsten auftretenden Bigramme.
| YI | GJ | GT | HG |
|---|---|---|---|
| 8 | 6 | 6 | 5 |
Da IY nicht im Text vorkommt, liegt der Schluss zu ch = YI nah.
- Aufschreiben der gefundenen Buchstaben.

Durch einfache Tests findet man schnell die Buchstaben für t und a sowie: t=L, a=W, u=N, w=P, g=H, m=F, b=X, d=Z, o=A, k=Z, l=R, v=O, z=V, y=U.
So heisst der nun geknackte Geheimtext:
Maruschka kommt - Übrigens hatte meine Schwiegermutter wieder mal Migräne - Meine Katzen habe ich gegen Zloty eingetauscht - denen ging es sowieso nicht besonders - Was macht Dein Hund? - Raucht er immer noch so viel?
Hilfsmittel zur Ver- & Entschlüsselung
Um Kryptoanalyse betreiben zu können, müssen wir uns mit den Gesetzmässigkeiten der Sprache vertraut machen. Jede Spracke hat solche Muster und diese können auch durch geschickte Chiffrierung nicht vollständig beseitigt werden.
Die Muster einer Sprache
Muster sind die Art und Weise, wie sich Buchstaben in einem Wort wiederholen. Sie werden über Ziffern ausgedrückt, wobei jeder neue Buchstabe auch eine neue Ziffer erhält, also z.B.:
OTTO---> 1221
NGRGUUV---> 1232445
PANAMAKANAL---> 12324252326
Solche Muster bleiben bei der monoalphabetischen Chiffrierung erhalten, d.h. enthält ein Geheimtext keine Muster, so ist er nicht durch monoalphabetischer Chiffrierung entstanden.
Die Abhängigkeit der Häufigkeiten vom Klartext
Die Angaben über die Einzelbuchstaben schwanken und hängen ausserdem vom Genre des Textes ab. Häufigkeiten sind um so schärfer, je länger der Text ist. So schreibt Beutelsbacher:
"Ein von Zitaten strotzender zoologischer Text über den Einfluss von Ozon auf die Zebras im Zentrum von Zaire wird eine andere Häufigkeitsverteilung aufweisen, als ein Traktat über die amourösen Adventüren des Balthasar Matzbach am Rande des Panamakanals."
Der Wortzwischenraum
Sicherlich kommen wir auf die Idee, den Wortzwischenraum (Space) mit zu verschlüsseln. Dies führt dann zu einem Alphabet mit 27 Buchstaben. Da der "Space" im Deutschen nach dem e das häufigste "Zeichen" und somit leicht zu enttarnen ist, lässt man diesen einfach weg.
Häufigkeiten von n-Grammen
-Gramme sind Kolonnen von Buchstaben. Die folgende Tabelle zeigt die Häufigkeiten für Bigramme im Deutschen und Englischen:
| Bigramm engl. | Häufigkeit in % | Bigramm dt. | Häufigkeit in % |
|---|---|---|---|
| th | 3.15 | en | 3.88 |
| he | 2.51 | er | 3.75 |
| an | 1.72 | ch | 2.75 |
| in | 1.69 | te | 2.26 |
| er | 1.54 | de | 2.00 |
| re | 1.48 | nd | 1.99 |
| on | 1.45 | ei | 1.88 |
| es | 1.45 | ie | 1.79 |
| ti | 1.28 | in | 1.67 |
| at | 1.24 | es | 1.52 |
Im Deutschen kommt ch sehr häufig vor, aber nahezu niemals hc. Ferner tauchen ei und ie gleich häufig auf.
Noch eine Tabelle mit der Häufigkeit einiger Trigramme:
| deutsch | Häufigkeit in % | english | Häufigkeit in % |
|---|---|---|---|
| ein | 1.22 | the | 3.53 |
| ich | 1.11 | ing | 1.11 |
| nde | 0.89 | and | 1.02 |
| die | 0.87 | ion | 0.75 |
| und | 0.87 | tio | 0.75 |
| der | 0.86 | ent | 0.73 |
| che | 0.75 | ere | 0.69 |
Abschliessend eine Aufzählung häufiger Viergramme:
deutsch:
icht,keit,heit,chon,chen,cher,urch,eich, ...
Aufschluss über den Ursprung des Textes kann übrigens auch die mittlere Wortlänge geben, oder die häufigsten Wörter. Betrachte dazu die folgenden Tabellen.
| Sprache | Wortlänge | Sprache | Wortlänge |
|---|---|---|---|
| deutsch | 5.9 | italienisch | 4.5 |
| englisch | 4.5 | spanisch | 4.4 |
| französisch | 4.4 | russisch | 6.3 |
| Sprache | Zehn häufigste Wörter |
|---|---|
| deutsch | die, der, und, den, am, in, zu, ist, dass, es |
| englisch | the, of, and, to, a, in, that, it, is, I |
| französisch | de, il, le, et, que, je, la, ne, on, les |
| italienisch | la, die, che, il, non, si, le, una, lo, in |
| spanisch | de, la, el, que, en, no, con, un, se, sa |
Die Abhängigkeit von der Verfassersprache
Häufigkeitsgebirge
Jede Sprache hat ihre eigenen Häufigkeiten. Die Diagrammdarstellungen werden Häufigkeitsgebirge genannt. Zwei Beispiele sind in folgender Abbildung illustriert:
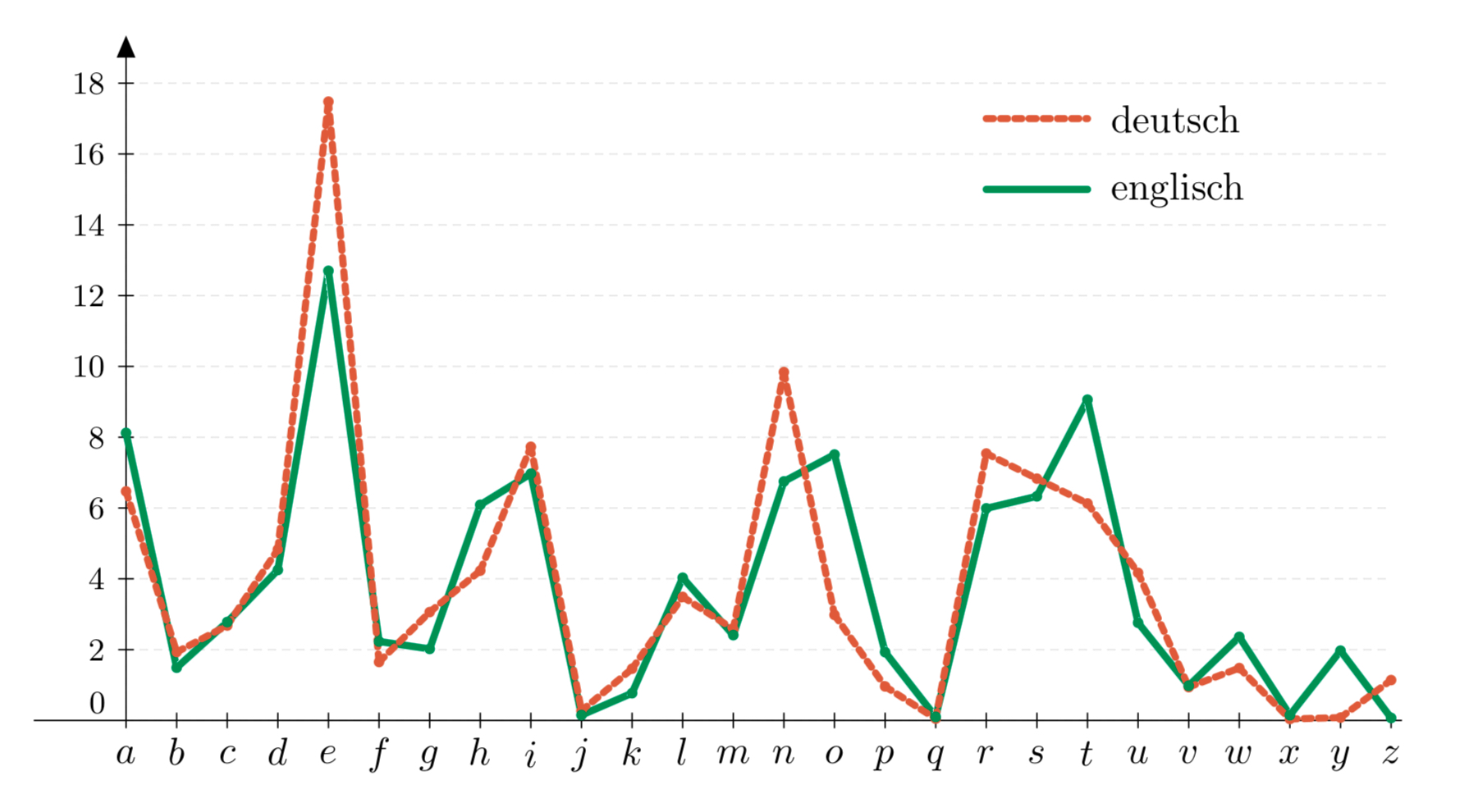
Durch Häufigkeitsgebirge können wir bei genügend langem monoalphabetisch chiffriertem Geheimtext feststellen, in welcher Sprache er verfasst wurde.
Der Koinzidenzindex einer Sprache
Um das einer Sprache zu bestimmen, schreiben wir zwei gleichlange unterschiedliche Texte untereinander und zählen alle "Spalten" mit gleichen Buchstaben. Anschliessend teilen wir diese Zahl durch die Anzahl der Buchstaben in einer Zeile:
Für zwei Texte gleicher Länge
definieren wir
ist. Praktischer ist jedoch die Formel
wobei die Gesamtanzahl der Buchstaben ist und die absolute Häufigkeit der einzelnen Buchstaben. Wir haben oben gesehen, dass jede Sprache ihr eigenes hat.
| Sprache | Koinzidenzindex κ (%) | Sprache | Koinzidenzindex κ (%) |
|---|---|---|---|
| deutsch | 7.62 | italienisch | 7.38 |
| englisch | 6.61 | spanisch | 7.75 |
| französisch | 7.78 | russisch | 5.29 |
| japanisch | 8.19 |
Kommt jeder Buchstabe (bei einem Alphabet von Buchstaben) mit der gleichen Wahrscheinlichkeit von vor, so ergibt sich
Durch Zerschneiden des Geheimtextes in zwei Hälften und der Ermittlung des der beiden so entstandenen Texte kann festgestellt werden, mit welcher Sprache der Klartext verfasst wurde oder ob es sich um eine Kunstsprache handelt.
Gegeben ist folgender monoalphabetischer Text. Versuche diese Nachricht zu knacken!
PEK MDIXKYAGU GNW KQR DHEILRU TXZF KHLZNXU GNTITAXUSIZ CANXPZAGKQR XPZGXZQTSA IEKKQN YBQR ULUDX AQSMZ USM LE VHU HOKAQIE DQNG KQR VPBHXYFEQA XAGN USM TAEZSUCAZF WXUUGX MQHELD EGATAXSF UGK SRTTYAMPWAEPECA RMTTZFRHWTAE PET SBPEF ZBIXSF DBL XAXUSE WLE GXDMEASFEG ZOHEBQSLLXWHYFEL BZD TBOH WLESXU CUTSUTTLF EBUQ WBJTTBNQ RHSXE PPQ MTU EIVO XEBJTT WLZKXU WAGU RAESE SBL PIXZQN KLXAMPH KNYLEG AQXM OMBXU WNTJWEG RAEGUQN LV SRTAGLBLDE BJT HXYLLBJT
Solution
Der Schlüssel ist math und damit wird der Text zu:
DER FRIEDMANN UND DER KASISKI TEST KOENNEN UNABHAENGIG VONEINANDER EINGESETZT WERDEN FUER BEIDE TESTS IST ES VON VORTEIL WENN DER CIPHERTEXT LANG IST MOEGLICHST WENIGE FEHLER ENTHAELT UND GRAMMATIKALISCH KATASTROPHAL IST ZUDEM SPIELT DIE LAENGE DES GEWAEHLTEN SCHLUESSELWORTES UND AUCH DESSEN QUALITAET EINE WICHTIGE ROLLE WIE MAN SICH LEICHT DENKEN KANN FALLS SIE DIESEN RELATIV KURZEN TEXT HABEN KNACKEN KOENNEN SO GRATULIERE ICH HERZLICH
Nach Bauer gilt:
Ein ideal für die Chiffrierung vorbereiteter Klartext ist orthographisch falsch, sprachlich knapp und stilistisch grauenhaft.
Man wollte nun diese "Schwächen" der monoalphabetischen Chiffrierung mit polyalphabetischer verschleiern. Polyalphabetische Chiffrierung bedeutet, dass das Prinzip der monoalphabetischen Chiffrierung nach gewissen Regeln ständig verändert wird. Es wird nicht der gesamte Klartext mit einem Schlüssel monoalphabetisch, sondern mit mehreren Substitutionen abwechselnd chiffriert.