Die Dichtefunktion einer kontinuierlichen ZV
Da die Häufigkkeitsverteilung von Datenpunkten einer kontinuierlichen Zufallsvariable mit Hilfe eines Histogramms veranschaulicht wird, sollte analog die Wahrscheinlichtkeitsfunktion einer kontinuierlichen Zufallsvariablen die Balkenhöhe des Histogramms approximieren. In der Tat, die Wahrscheinlichkeitsfunktion soll ja die Verteilung der Wahrscheinlichkeit über die möglichen Werte von , oder angenähert, die Datenpunktverteilung im Datensatz, als Funktion darstellen. Aber für welches Histogramm? Je nach Klassenbreite kann das Histogramm ja ganz verschieden aussehen. Um dieses Problem zu umgehen, konstruieren wir unser wie folgt:
Gegeben sei ein Experiment mit einer kontinuierliche Zufallsvariable , dessen möglichen Werte im Intervall liegen, wobei und ebenfalls möglich ist.
- Wir führen das Experiment mal durch, wobei wir extrem gross wählen, so dass wir extrem viele durch erzeugte Datenpunkte erhalten.
- Wir formen das Histogramm der erhaltenen Datenpunkte. Da wir extrem viele Datenpunkte haben, können wir die Klassengrössen extrem klein wählen. Je mehr Datenpunkte wir wählen, und je kleiner wir die Klassenbreiten machen, desto glatter wir das Histogramm. Dies ist in der Animation unten illustriert. Die glatte Kurve ist die Wahrscheinlichkeitsfunktion von , welche im Grenzübergang für unendlich viele Datenpunkte und unendlich kleine Balkenbreiten erhalten wird.
Beachte, dass eine Dichte ist, da die Höhe des Histogramms eine Dichte ist (relative Häufigkeit durch Klassenbreite ). Wir nennen deshalb die Wahrscheinlichkeitsdichtefunktion (oder kurz Dichtefunktion) von .
Es ist zu beachten, dass wir mit Hilfe dieser Konstruktion nur bewiesen haben, dass es so ein Funktion gibt, und wie deren Graph aussieht. Das heisst aber nicht, dass wir vom Histogramm auf die algebraische Form (die Formel) von schliessen können. Manchmal ist es einfach, die algebraische Form vom Graphen abzulesen, meistens ist es aber nicht trivial, wie wir ja schon von den verschieden diskutierten Funktion wissen.
Hier sind die wichtigsten Eigenschaften von .
Gegeben sei eine kontinuierliche Zufallsvariable , deren Werte im Intervall liegen ( und können auch sein), und sei die dazugehörende Dichtefunktion. Es gilt:
-
für alle
Der Graph von liegt nie unterhalb der -Achse.
-
für jedes Intervall
Die Fläche unter der Kurve von bis ist die Wahrscheinlichkeit, dass einen Wert im Intervall annimmt.
-
Die Fläche unter der Kurve von nach ist .
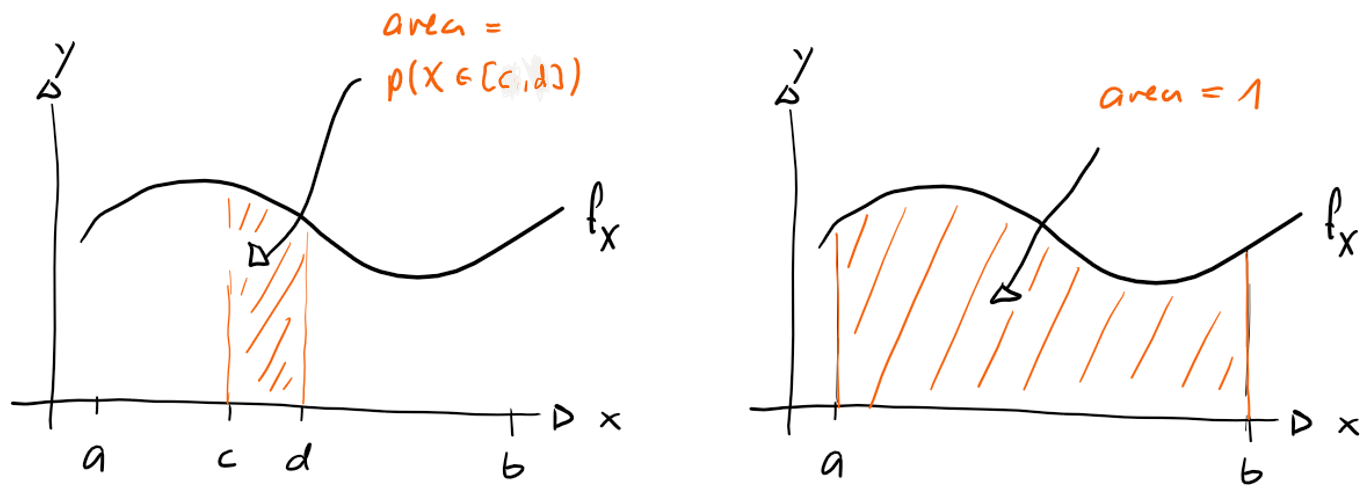
Proof
Wir geben nur intuitive Beweisskizzen. Für formale Beweise brauchen wir eine grössen mathematischen Apparatus, den wir hier nicht entwickeln.
-
Die Höhe der Balken im Histogramm (Dichten, also relative Häufigkeit über Balkenbreite) ist nie negative. Da ebenfalls Balkenhöhen sind (für super schmale Balken), muss ebenfalls gelten .
-
Wir wissen schon von der Integralrechnung her, dass das Integral durch die Summe von Balkenflächen approximiert werden kann
Und je grösser (mehr Balken), desto besser diese Approximation. Wie immer sind die Punkte der Ort der Balken auf der -achse ziwschen und (rechte Seite des Balken). Beachte nun, dass die Balkenfläche ungefähr die relative Häufigkeit der Datenpunkten im Intervall ist, (da ja $f_X(x_k) die Dichte approximiert). Wir haben also
Die Summe dieser relativen Häufigkeiten ist also die relative Häufigkeit der Daten im Intervall . Und je mehr Datenpunkte wir haben, und je mehr Balken wir brauchen, um das Integral zu approximieren, desto mehr nähert sich diese relative Häufigkeit der Wahrscheinlichkeit an.
Wir sehen also, dass sein muss.
-
Wegen (keine anderen Werte möglich für ) und (siehe Punkt (2) oben) folgt .
Oft werden Punkte (1) und (2) im Satz oben verwendet, um formal die Dichtefunktion einer kontinuierlichen Zufallsvariable zu definieren, daher wir könnten definieren, dass eine Funktion eine Dichtefunktion von ist, falls gilt, dass
- für alle
- für jedes Intervall
Der dritte Punkt, dass , folgt dann, wie schon oben, aus Punkt (2). Unser Vorgehen ist etwas intuitiver.
Im Prinzip kann jede Funktion (zumindest diejenige, die wir kennen) die Dichtefunktion einer Zufallsvariablen sein. Oft kennen wir weder , noch das Experiment näher, und postulieren einfach ein mit einer bestimmten Dichtefunktion , wobei irgendeine Funktion sein kann. Wir müssen einfach darauf achten, dass und die Fläche unter der Kurve ist: . Unten ist ein Beispiel.
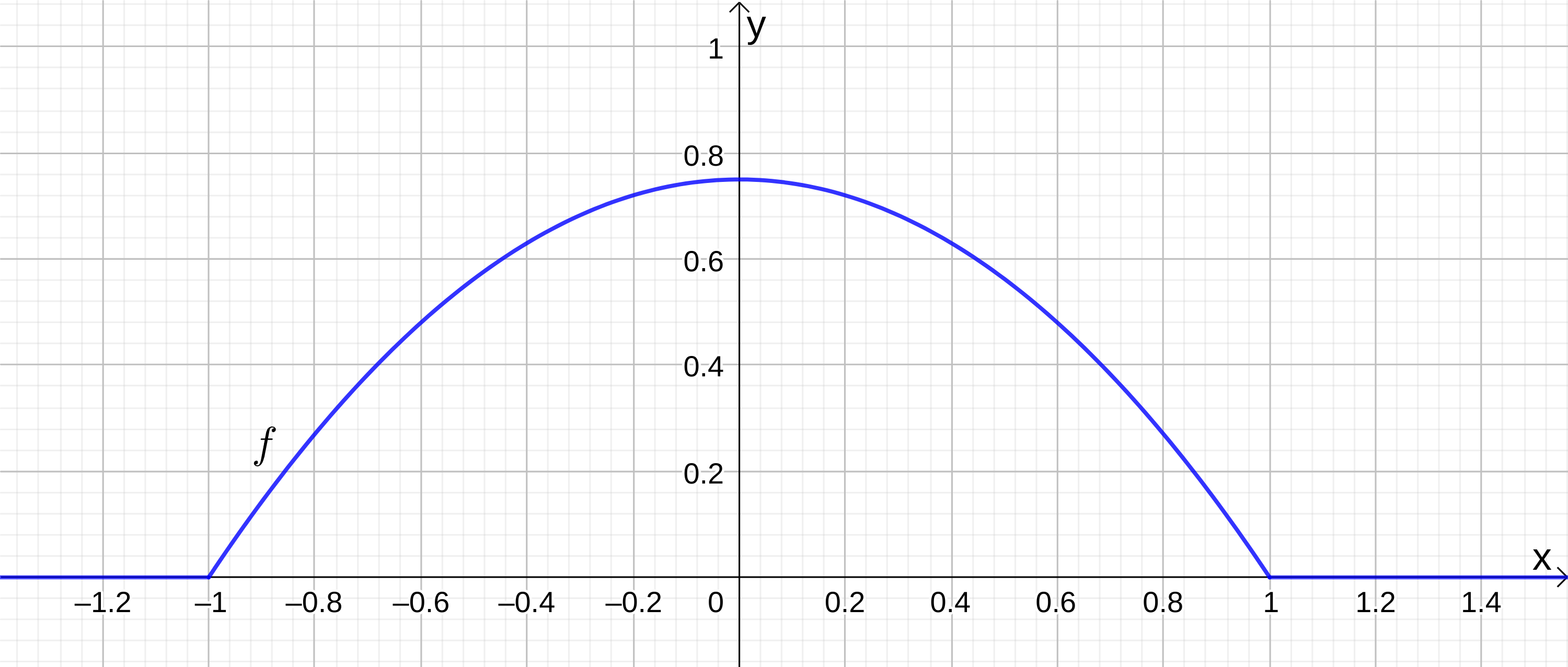
Man betrachte ein Zufallsexperiment mit einer kontinuierlichen Zufallsvariablen , welche mögliche Werte in besitzt, und deren Dichtefunktion gegeben ist durch
-
Skizziere den Graphen der Dichtefunktion .
-
Überprüfe, dass
-
Bestimme die Wahrscheinlichkeit, dass der beobachtete Wert von zwischen und liegt.
-
Bestimme
Solution
Die Stammfunktion von is
-
Der Graph von ist
-
Es ist
-
Es ist
-
. Gilt auch für alle anderen Werte, nicht nur für .